2.1.2.2 LZ - algorithms
The basic idea of dictionary based compression mechanisms (also called textual substitution methods) is to use a fixed or dynamic indexed set of words(or phrases) D called dictionary to store strings. By replacing substrings form D in the input stream with the corresponding index(or pointer) into D we expect to obtain a more compact representation of data. The result of the compression scheme will be a string of pointers or a mixture of pointers and row data (from the initial source) using a method to make the difference between those two type of outputs.LZW dictionary compression
Most practical compression algorithms use dynamic dictionary schemes, introduced by Ziv and Lempel; dictionary is is constructed incrementally while reading the input symbol by symbol and some of its factors are chosen as dictionary phrases. Usually, the dictionary satisfy the prefix property: in any execution step of the algorithm, for any given phrase in the dictionary, all its prefixes are also phrases in the dictionary.Further we focus on the LZW scheme improuved by T. Welch. The LZW algorithm parse the input string into blocks in the following way, adding blocks to dictionary in the same time.
Input:w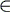 V*
V*
1.position := 0;D := V;
2.while (position < |w|) do begin
3. find the longest word w' with the following property:
exists B D such that
w' = w[0..position]B;
4. encoded position of B in the dictionary D
using log2(|D|) bites;
5. if ( |w'| < |w| ) then
add to dictionary thw block B' := B w[position + |B|]; D := D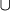 { B' };
{ B' };
end if
6. position:=|w'|;
end while.
V* 1.position := 0;D := V;
2.while (position < |w|) do begin
3. find the longest word w' with the following property:
exists B
D such that
w' = w[0..position]B; 4. encoded position of B in the dictionary D
using log2(|D|) bites;
5. if ( |w'| < |w| ) then
add to dictionary thw block B' := B w[position + |B|]; D := D
{ B' };end if
6. position:=|w'|;
end while.
LZW variant used in UNIX compress tool use a series of improvements; the most important one is instantaneous useful dictionary:
- if in the S-th execution step of the algorithm the
choused word is B and dictionary contains words like
B x
where x V, in the following step of the algorithm we
can ignore strings from the dictionary of the form x w where
x w V+.
